
業務改善、可視化|知る×学ぶ
データとAIのフル活用を進める方法|課題となりやすいポイントと解決方針
クラウド技術やAIの技術革新が進み、社内の誰もが簡単にデータとAIをフル活用できるような環境を構築することが現実となりつつあります。
米国を中心とした海外ではこの流れの変化をData Democratization(データの民主化)やAI Democratization(AIの民主化)と呼び、ビジネス変革を推進する原動力として大きな期待を寄せているようです。
この「データとAIの民主化」が注目されているわけをご理解いただくために、連載コラム「データとAIの民主化シリーズ」第1回ではデータドリブン経営を実現するためにデータとAIのフル活用を進めている海外の最新事例と国内トレンドを含めてお伝えしました。第2回ではデータとAIの利活用を進める上で課題となりやすいポイントやどのように進めていくべきかについて、データブリックス・ジャパン株式会社パートナー・ソリューション・アーキテクトの竹下 俊一郎氏がその具体的なイメージを明らかにしてまいります。

▼ 目次
1.ポイントはシンプルな基盤と人材育成
戦略、担い手、プロセス、データ、テクノロジー
2.一向に進まないデータとAIの利活用推進
3.データとAIの利活用推進に必要な要素・機能
○ STEP 1:企業内外データを分析可能な状態に
○ STEP 2:データに付加価値を追加
○ STEP 3:データ活用の効果を測定する
○ STEP 4:社内外でデータ共有を行おう
4.D-Nativeで進める課題解決型アプローチ
5.データブリックスによる多様な機能群をシンプルに使う
1.ポイントはシンプルな基盤と人材育成
前回(連載コラム「データとAIの民主化シリーズ」第1回)はレイクハウスというシンプルな基盤が データとAIのフル活用を支えているとお話ししました。実際に、米国でテックカンパニーと言われるMeta社、Netflix社、Uber社等はどのように基盤構築を行ってきたでしょうか。
先進的な企業は、100億円以上のコスト、1000人以上の優秀なエンジニア、10年以上の長い期間をかけて構築しています。それが現在 SaaS型の分析基盤が出てきて数クリックで非常に短期間で基盤ができる時代になっています。
今後のデータとAI領域の展望はどのようなものでしょうか?前回で触れた「Data + AI Summit 2022」において弊社製品開発責任者のDavid Meyerが日本向けに下記のメッセージを語ってくれました。
“現在は人材不足も言われていますが、今後5年以内に誰でもデータやAIを使えるようになると思います。なぜかというと、私たちがデータもAIも、ものすごくシンプルにしていくからです。使われる方全員が「今やってることって本当にデータとかAIを活用していることなの!」とびっくりするぐらい、簡単で、誰でも直感的に使えるようにしていきたいと考えています。年齢も関係なく、“誰でも”使えるということを念頭にしています。”
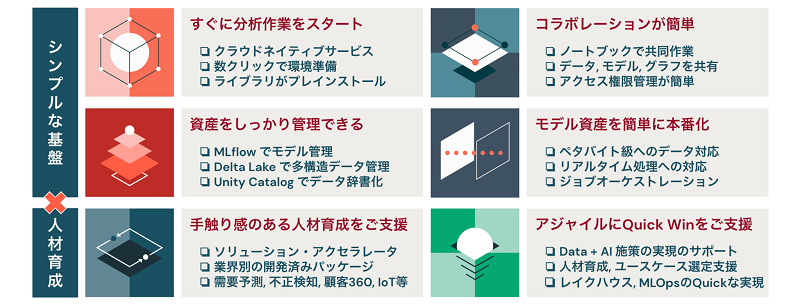
図1:レイクハウスがデータチームに評価されているのはシンプルな基盤と人材育成
また、Databricks社として提供するのは単なるプラットフォームではありません。さらなるデータ活用のために大きく2つのサービスを展開しています。ひとつは人材育成支援、もうひとつはQuick Winをアジャイルに支援するものです。
世界中の成功事例を教材として提供することで、人材不足やPoC止まりで実ビジネスに応用できないといった問題を根本的に解決することを考えています。
2.一向に進まないデータとAIの利活用推進
前項では、データとAIをフル活用していくにはシンプルな基盤と人材育成が必要であるとお話ししました。それでは再度、足元の日本の事例について考えてみましょう。
<国内企業がAIの利活用において課題となりやすいポイント>
① 戦略の視点:「そもそもデータとAI活用で何を実現するかの方向性が不明」
② 担い手の視点:「データはあるが、それをフル活用できる人材が不足しておりプロジェクトが進まない」
③ プロセスの視点:「データとAIを活用する業務プロセスが属人的であり、不透明かつ活用領域が限定的な状況に陥ってしまっている」
④ データの視点:「AI活用以前の課題であるが、そもそもデータが散在している状態でありAI活用データ活用の土俵に立てていない」
⑤ テクノロジーの視点:「データ基盤構築において登場するテクノロジーやサービスが多岐に渡り、作業が複雑で、構築・運用・管理で手詰まり。また、データ量の増加やデータの種類の多様化により、やりたいことが実現できない」

そのような声をお聞きすることも少なくありません。実はこれは日本に限ったことではありません。データとAI活用が進まないと考えている企業は米国でも90%以上を超えており、上記のような課題に集約されます。
しかし、ここ数年来の技術革新により「③ プロセスの視点」「④ データの視点」「⑤ テクノロジーの視点」はつまずきから解放されることが割と簡単になってきています。
では具体的にどのようなサービスを利用することが推奨されるでしょうか?
第1に、Amazon Web Service、Microsoft Azure、Google Cloudなど、クラウドベンダーサービスの機能を活用するのも選択肢です。ただし、注意しなければならない点もあります。これらのサービス群ではデータとAI機能一つをとっても無数に提供されています。少数精鋭の優れた技術者により、これら多様なモジュール群を組み合わせてデータとAIのプロジェクトを進めることは可能といえます。
一方で組織の拡張に伴い、多様なレベル感の人材を駆使しながらプロジェクト推進する際には壁にぶち当たることが多くなっています。
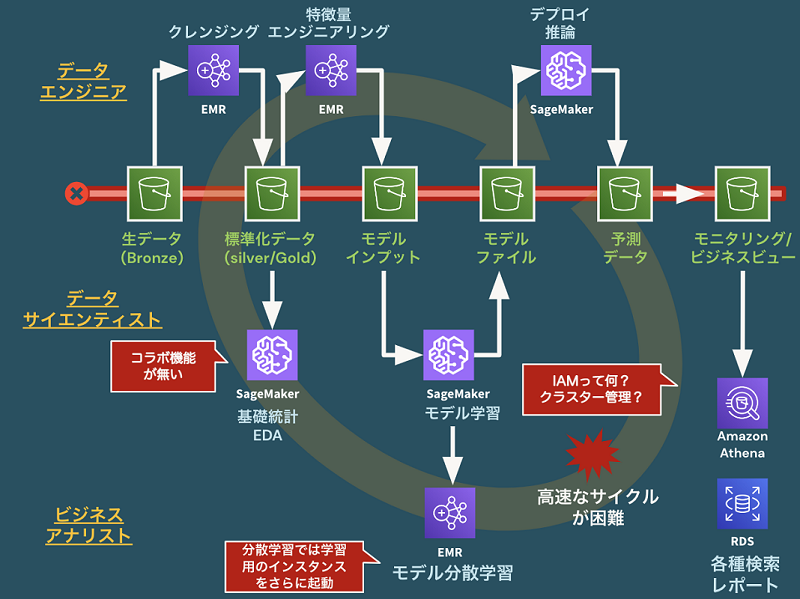
図2:クラウドサービスの組み合わせはデータとAIのフル活用において組織の壁に突き当たる
第2に、クラウドデータウェアハウス(クラウドDWH)を活用することも選択肢です。ただし、同様に注意しなければならない点もあります。現状を把握するための可視化という点では有効であるかもしれませんが、クラウド型のDWHですら従来型のテクノロジーであり、BIの世界にとどまります。未来を予測しデータとAIをフル活用するには、別途基盤を用意する必要があります。それはデータレイクと言われたり、機械学習基盤と言われたりします。
実は以下の図のように新たな課題が生じることが明らかになっています。ここでは代表的な課題を3つ挙げます。
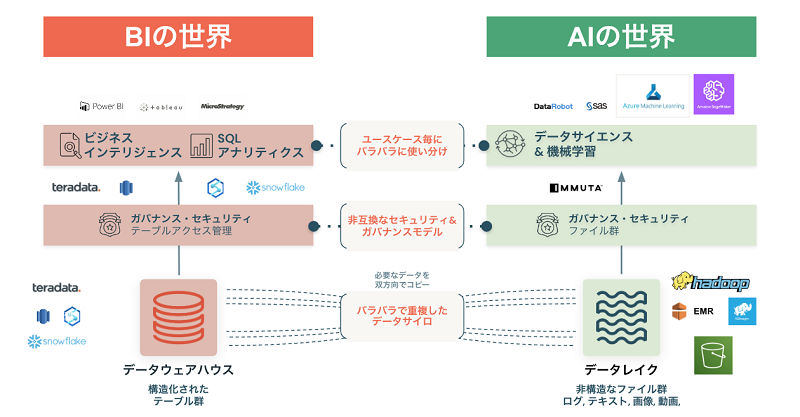
図3:クラウドDWHではデータとAIのフル活用において新たな壁に突き当たる
第1に、せっかくクラウドDWHにデータを集約できたと思っても新たなデータサイロ化に直面します。オンプレミスの世界をクラウドに移しただけの企業をたくさんお見受けします。連載コラム「データとAIの民主化シリーズ」第1回の海外最新事例でも触れましたようにデータによる現状の可視化だけでは不十分で予測やシミュレーションが不可欠です。クラウドDWHではその機能が無いかもしくは限定的であり、新たにデータをコピーしたり、予測やシミュレーションを行ったりする他のツールを導入する必要があります。また、予測やシミュレーションの精度を上げるにはコールログ、音声、動画などの新たな形式のデータをインプットとして必要とします。これらの非構造化データを扱うのもクラウドDWHが苦手とする点です。一部の製品は格納ができますが、データサイズも非常に大きくコスト効率も良くありません。このようにつぎはぎもしくは発展途上のテクノロジーを無理に使うことで、新たなデータサイロという悩みが出てきます。
第2に、データセキュリティの課題です。データとAI活用は攻めつつ守ることも必須となっています。非常にセンシティブなデータを扱うためアクセス制御や暗号化等のセキュリティやガバナンスも必要となります。また、データカタログに代表されるデータ辞書、データ品質、データ来歴も要件として求められます。注意すべきは、BIの世界では、その多くがテーブルと言われる形式で格納されている一方で、AIの世界ではその多くがファイル形式(CSV、JSON、Parquet、Delta Lakeなど)で格納されています。このようなテーブルの管理とファイルの管理と相容れない非互換なセキュリティ・ガバナンスモデルを統合することに頭を悩ませることとなります。
第3に、データを利活用するためのインターフェースがバラバラになります。このことにより、本当はデータとAIのフル活用を全社的に行いたい一方で、ツール毎、組織毎、プロジェクト毎に分断され、属人化の一途をたどることとなります。
このようにクラウドDWHでデータを整理したつもりが結局、最初の地点のデータサイロ化という課題に再び直面することになると、しっかりと認識すべきです。
3.データとAIの利活用推進に必要な要素・機能
このようなお客様の声を踏まえて登場したのがデータブリックスのレイクハウスです。その過程を一つずつご紹介していきます。
まずは、一番下のストレージ層です。データブリックスのレイクハウスはストレージ層としてクラウドストレージ(オブジェクトストレージ)を採用しています。データブリックスではデータを保存せずお客様のクラウドストレージをそのまま利用可能です。新たなデータコピーによるデータサイロ化を最小化することも考慮されています。また、クラウドDWHに比して安価でスケーラブルでセキュアなストレージかつ、有効なデータソースであるファイルベースのコールログ、音声、動画等の非構造化データも格納可能となります。
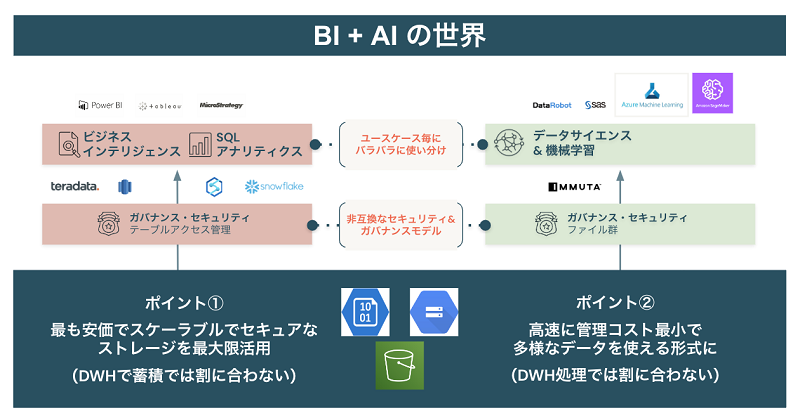
図4:レイクハウスは安価でスケーラブルなクラウドストレージを採用
そして、これら多様なデータに対して高速処理も可能になってきています。
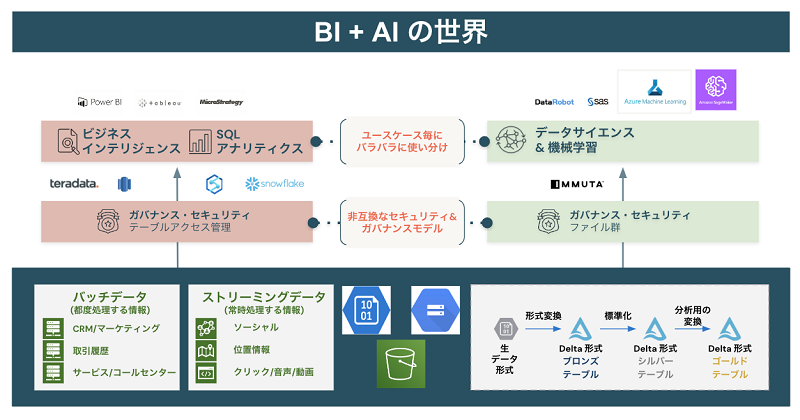
図5:レイクハウスは非構造化データも高速に処理可能なクラウドストレージ
次に、真ん中のセキュリティとガバナンス層です。データブリックスのレイクハウスはUnity Catalogという機能を採用しています。Unity Catalogでは構造化データから非構造化データを含む多様なデータの辞書化、データ来歴(データリネージ)の機能も有しています。また、データのみならず機械学習モデルもカタログ化の対象であり、データとAIをフル活用する際の立役者となります。
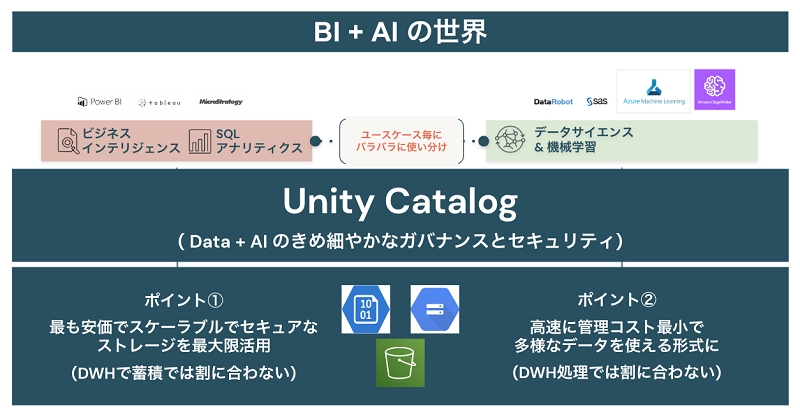
図6:レイクハウスは全てのデータオブジェクトや機械学習モデルをカタログ化
一部ではありますが、Unity Catalogの画面を紹介いたします。左側が欲しいデータを探したり、データの意味合いを理解したりする画面で、右側がより高度な使い方です。データをより深く理解するため、このデータがどこから来たのか、どのデータと組み合わせて加工されたのか等、データの来歴(データリネージ)を調査することが可能です。
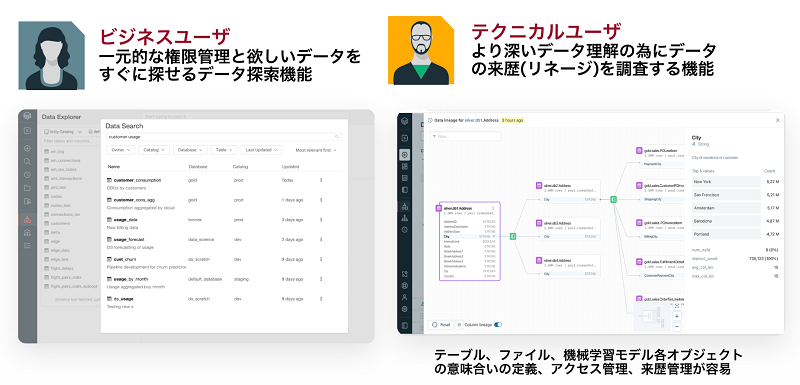
図7:レイクハウスは多様なユーザのデータ理解を支援
最後に、一番上のユーザが利用するインターフェースの層です。データブリックスのレイクハウスはBIからAIまでを実行可能な多様な画面を有しております。
- データウェアハウス :SQLで非定型な検索を行ったり、BIツールで定例レポートを参照したりすることができます。
- データエンジニアリング :大量のデータを加工したり、データ品質管理を行い不要なデータを削除したりすることができます。
- ストリーミングアナリティクス :バッチ処理として昨日のデータを加工することや参照するのみならず、ニアリアルタイムに最新データを連携し加工参照ができます。
- データサイエンス・機械学習 :Notebook形式でpythonやR等で機械学習モデルを作成したり、GUIベースでAutoML(Automated Machine Learning)を行なったりすることができます。
- ソリューションマーケットプレイス :有用なデータのみならず、ダッシュボードや機械学習モデルを社内外にセキュアに共有することができます。
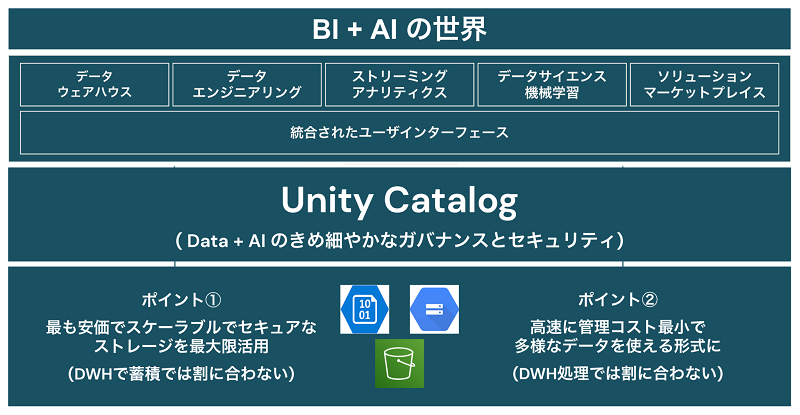
図8:レイクハウスは BI + AI を実行可能な統合されたユーザ画面を搭載
各ユーザインターフェースの画面サンプルは本記事の最後でご紹介します。
少し長くなりましたが、ここ数年来の技術革新により「プロセスの視点」「データの視点」「テクノロジーの視点」はつまずきからの解放が容易になってきたことがご理解頂けたでしょうか?
最後に、データブリックスレイクハウスのアーキテクチャ概要を記述しておきます。こちらの方が理解しやすい方もいらっしゃるかもしれません。緑の箇所が対応可能な範囲です。
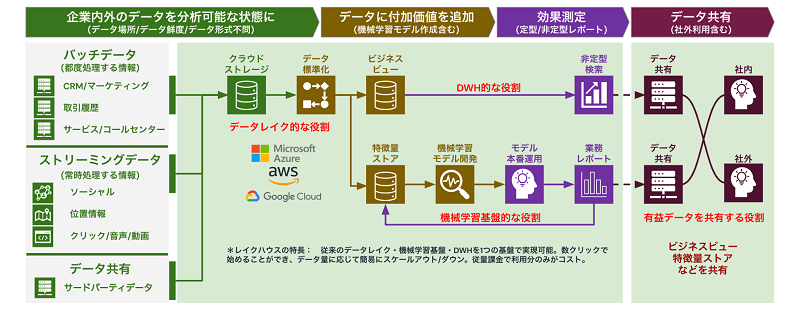
図9:データブリックスレイクハウス のアーキテクチャ概要
4.D-Nativeで進める課題解決型アプローチ
前項では、「③ プロセスの視点」「④ データの視点」「⑤ テクノロジーの視点」のつまずきポイントは データブリックスのレイクハウスにて解消されることを解説しました。
あとは、「① 戦略の視点」「② 担い手の視点」ですね。
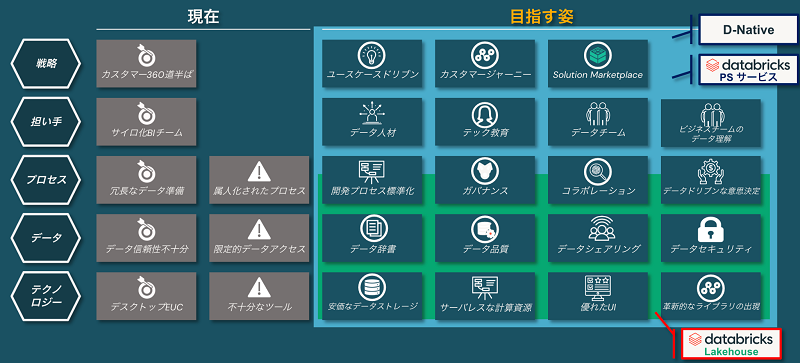
図10:データとAI利活用推進の課題となりやすいポイントと解決のイメージ
そこでD-Nativeです。
D-Nativeは国内企業がデータドリブン経営を促進できることをご支援することを目的として発足しました。データドリブン経営とは、既存の経営の指標に捉われることなく企業に存在するデータを組み合わせ、分析し、それを経営に活かすこと、とここでは定義します。
そのためには、企業に存在するデータを整理し、必要な人が必要なデータに必要な時にアクセスできる仕組みづくりが必要と考えています。
その際に、課題となりやすいポイントが3つあると考えています。
- 推進体制:どのような体制を組んでデータとAIをフル活用していくか
- テーマ検討:どのようなテーマでデータとAIを進めていくか、初期テーマの設定と中期的なテーマのロードマップ
- 基盤検討:そのテーマをどのようなデータ基盤とAI基盤で実施するか
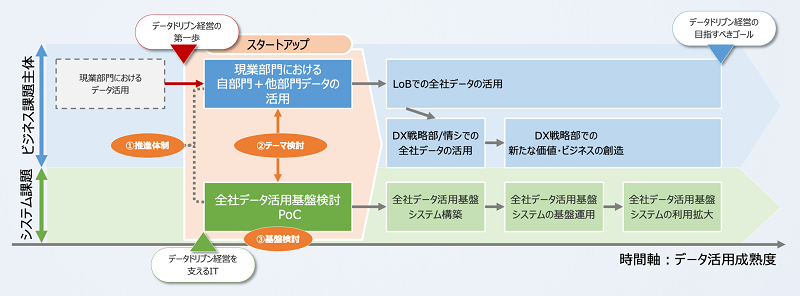
図11:データドリブン経営に向けてデータ活用の成熟度を高めるステップの例
基盤検討については前項で触れましたので、ここでは推進体制とテーマ検討に触れます。
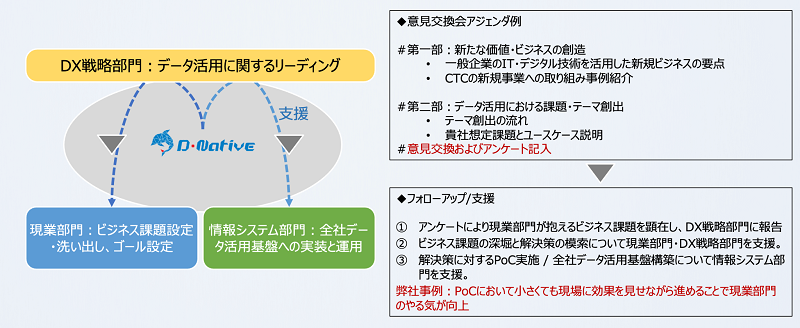
図12:推進体制の一例(D-Nativeの場合)
まずはデータドリブン経営実現に向けた推進体制です。典型的な推進体制では3つの部門から構成されることも多いかと考えております。
- DX戦略部門:データ活用に関するリーディングを行う部門
- 現業部門:ビジネス課題設定や洗出しを行ったり、ゴール設定をしたりする部門
- 情報システム部門:全社データ活用基盤への実装と運用を行う部門
これらの3部門が同じ方向を向き、3つの車輪で動き出さなければ上手くデータとAIのフル活用がなされないことが散見されます。D-Nativeを活用することで、これまでの成功事例を主軸に意見交換を行ったり、フォローアップを行ったりすることで推進体制が円滑に活動することが可能となります。
次はテーマ検討です。中期的なゴールを描きつつも足元の課題により、データ活用はすぐには進まないと頭を悩ましている方も少なくないと想像しています。
- 「そもそも、現状を定量的に測定できず、目指すゴールも決められない。」
- 「現状が定量的に測定できていないのは、部署間でマスターデータが異なったり、そもそもデータの意味や定義が曖昧だったり、データ品質が低い」
この場合、データが揃っているテーマから優先して進め、その間に不足が分かっているデータやクレンジングを対処していき少しずつ成果をだしていくいわゆるアジャイルな方式が成功パターンとなっています。アジャイル型のアプローチでは、定期的にゴールを見直し優先度を鑑み軌道修正をしていくことが求められます。とはいえ、やみくもにゴールなしに進むわけにはいきません。優先度の高いビジネス課題に取り組む必要があります。
その道しるべが、ユースケース一覧であり、連載コラム「データとAIの民主化シリーズ」第1回で少し触れましたDatabricks ソリューションアクセラレータです。同業他社事例・同種業務における活用例から、自社でのデータ活用イメージを明瞭化することができます。また、実際に試してみたいという方には、サンプルデータとサンプルノートブック(機械学習のサンプルモデル)の活用も可能であり、自社データと組み合わせてクイックにビジネス価値を出せる支援が可能です。また、人材の育成観点からも実業務に近い形で学ぶことで有効です。
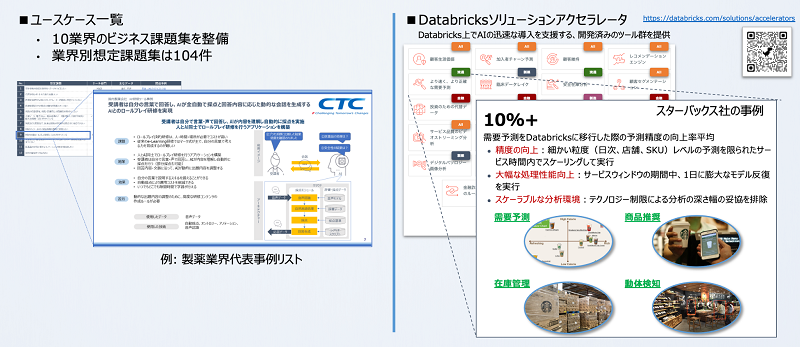
図13:データドリブン経営実現の道しるべとユースケースや同業他社の事例
5.データブリックスによる多様な機能群をシンプルに使う
それでは最後に、データとAIの民主化を強力にご支援するデータブリックスの最新機能をお伝えします。
- Databricks SQL :
SQLで非定型な検索を行ったり、BIツールで定例レポートを参照したりすることができます。数十や数百の利用ユーザが来たとしてもバックエンドのコンピュータリソースがスケールします。コンピュート層とストレージ層が別々にスケール可能であり、次世代型のDWHとして利用可能です。 - Databricks Notebook & AutoML :
Notebook形式でpythonやR等で機械学習モデルを作成することが可能です。またNotebookはチーム間で共同作業ができ属人化の排除、生産性の向上が可能です。また、所謂シティズンデータサイエンティストもGUIベースでAutoMLを行なったりすることができます。 - Databricks Delta Live Table :
ワークフローによるデータオーケストレーションが可能です。データパイプラインの構築・管理が容易に実現できます。スケジュール機能で定期的に処理を実行したり、場合によってはデータ品質ロジックを埋め込みデータ品質管理をしたりすることができます。 - Databricks Unity Catalog :
構造化データから非構造化データを含む多様なデータの辞書化、データ来歴 (データリネージ) の機能も有しています。また、データのみならず機械学習モデルもカタログ化の対象となります。
図14:データブリックス レイクハウス のユーザ画面の一例
今回はデータとAIの利活用を進める際に課題となりやすいポイントと解決方針を明らかにしてまいりました。第3回では「データとAIの利活用を進める際どこから着手するべきか」についてお話ししていきたいと思います。

\ “データとAIの民主化”関連記事が公開されたらメールでお知らせいたします! / → メルマガ登録

□ お問い合わせ
- データブリックス: データブリックス・ジャパン株式会社 marketing-jp@databricks.com
- D-Native: 伊藤忠テクノソリューションズ株式会社 dsbp-contact-us@ctc-g.co.jp