SAP、基幹システムクラウド
機械学習の課題を解消できるSAP Predictive Analitycsとは|データ活用でビジネス利益を最大化
ビジネスの利益を最大化する重要要因として顧客データが重視されつつある昨今、Web、SNS、アプリ、メール、IoTなど企業と顧客を繋ぐデジタルチャネルから得られるデータを機械学習やデータマイニングで分析して活用する動きが加速している。
データの分析と聞くと「データサイエンティスト」という職種が思いつくが、必ずしも部署内にデータを分析・活用できる担当者がいるわけではない。
むしろ重要なことは、部署内の誰もが「ビジネスの現場に即した数字の見方ができるようにする」ことではないだろうか。
そこで本記事ではデータ活用によるビジネスの競争力の強化を模索されている方に向け、「誰でも」「いつでも」「簡単に」「早く」データを活用するための方法について解説する。
▼ 目次
・機械学習とデータマイニングの違いとは
・顧客の購買や反応を機械学習から予測する
・機械学習の課題を解消できるSAP Predictive Analyticsとは
・SAP Predictie Analyticsの強み
1. 機械学習とデータマイニングの違いとは
まずは機械学習とデータマイニングの違いについて解説する。
※違いをイメージしやすいよう、数多の機械学習・データマイニングの活用方法をあえて限定的に記述している点をご了解いただきたい。
1-1. 機械学習の目的
機械学習の目的は結果が重視されている。
例えば、人は天気予報で「降水確率80%」という結果を聞くと、「今日は傘を持って出かけよう」という意思決定を下す。この場合、降水確率の算出方法や雨が降る仕組みにはフォーカスを当てず、この「80%」という数値をベースに戦術的な意思決定を下して行動に移す。
莫大なデータから、このような意思決定を強力に支援する信頼できる数値を算出することが、機械学習の目的である。

1-2. データマイニングの目的
データマイニングの目的は、莫大なデータの中から、「どうして雨が降るのか?雨が降る時はどのようなデータが関連しているのか?」など未知のルールを見つけ出し、データから現象を深く理解して業務に活かすことである。
データマイニングは、データから仮説を発見することが重要であるため、分析する人間のビジネスやテクノロジーに関する知見、専門的スキルや経験が必要となる。

1-3. ビジネスへの機械学習、データマイニングの応用
ビジネスシーンにおいて機械学習とデータマイニングのどちらのアプローチの選択するべきか検討する際は、目的に照らし合わせて考えれば良い。
- 分析作業に入る前に即業務に活用できる数値が欲しい
- データの中に潜む未知のルールを見つけたい
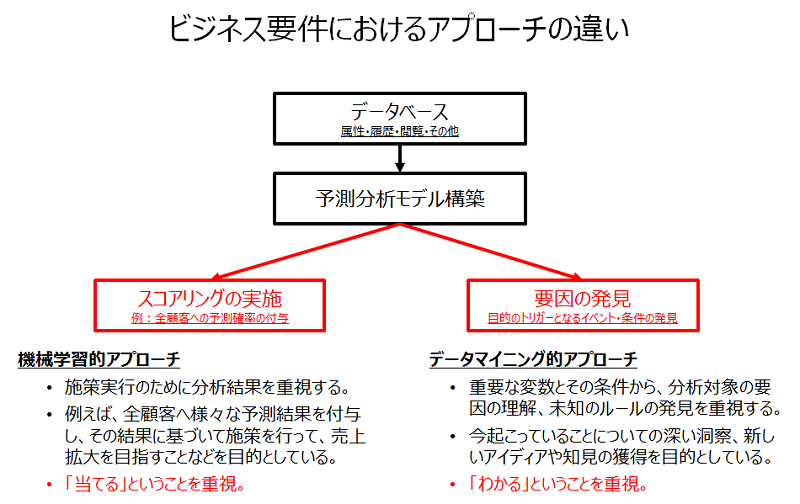
図 1. ビジネス要件におけるアプローチの違い
また、一つの作業によって上記の二つのアプローチを同時に実行できるように考えられているが、実業務では大きくプロセスが異なるため、分析目的およびアプローチ方法を厳密に分けて考えた方が良い。
まずはビジネスのテーマとして、「当てたい」のか「知りたい」のかをよく考えることが重要となる。
2. 顧客の購買や反応を機械学習から予測する
機械学習には以下の活用方法がある。
- 顧客の購買や反応を予測する際に利用される「分類」
- 顧客の行動や振る舞いから類似したグループに分ける「クラスタリング」
- 時間とともに変化する値を予測する「時系列分析」
ここでは、様々な場面で多く活用される「分類」による予測分析モデルにフォーカスする。

機械学習は、過去に発生した結果から学習をすることで予測式を導き出す。
したがって、過去に発生した事象が対象となり、それらをデータとして分析を行う。
この時に重要となるのが、分析結果をビジネスに活用し収益を得るために実際にアクションを起こすことである。
企業での活用事例としては、過去に発生した事象に対してその発生確率を算出し施策に活用するという流れが多い。
予測分析モデルを構築することで下記が可能になる。
- 購買履歴データから将来の購入予測確率を顧客に付与
- 過去のキャンペーンの履歴からキャンペーンの反応確率を算出
- 製造工程におけるマシンログから不良品の発生確率を算出
機械学習による予測分析モデルを業務へ適用するために注意すべきことは、単に予測確率を算出するだけでなく、算出結果をビジネスにどう活用するかを事前にきちんと検討しておく必要があるという点だ。

購入確率が判明すれば、下記の検討に進むことができる。
- 顧客別に購入促進のキャンペーン施策を迅速に実施することができるのか
- ROIは改善するのか
- 不良品の発生確率が判明すれば、即座に不良品を生産の工程から除外やリワークに回したりできるのか

もし、算出結果を業務に活かしても、収益の改善に貢献ができなければ「機械学習はビジネスに貢献できないもの」というレッテルが貼られてしまう。
このような間違った結果を導かないようにするため、機械学習を活用した予測分析のプロジェクトなどを立ち上げる場合には、下記を事前に検討した上で進めていく必要がある。
- どのような結果を導き
- どのような業務で活用するのか
データさえあれば、どのような戦略を立ち上げ、どのような施策を打てば良いかなどを機械学習が自動的に学習・検討し、提示してくれるわけではない。
業務担当者が立案した戦略に対して、その戦略を実現するために、最も効率的な施策を遂行する戦術の強化をもたらすものが機械学習であり、それを理解した上で我々も活用する必要がある。
3. 機械学習の課題を解消できるSAP Predictive Analitycsとは
機械学習による予測分析モデルを構築するためには、ビジネスに適用するための下記のステップを踏む必要がある。
- 計画立案
- データの整理
- アルゴリズムの選択と活用
その中で、特に阻害要因となりやすいのが、機械学習で活用するアルゴリズムを選択し、設定、実行する部分である。
これには高度な知識が必要となるため、結局どのアルゴリズムを選択しどう設定するのかは、人のセンス・知識・経験がベースとなる。
よって、経験がない人が実施する場合、全てのアルゴリズムを試し何が一番良いのかを判断することとなる。さらに、アルゴリズムの制約に基づいたデータ加工や項目の準備、変換をしていかなければならない。業務担当者が忙しい日常業務の中でこれらの作業を行うのは不可能であるため、実際はデータサイエンティストや分析担当者が時間をかけて行うこととなる。ここでまた、データ活用がスムーズに進まないという課題を招きやすい。

このような課題を解決する手段として「SAP® BusinessObjects™ Predictive Analytics(以下、SAP Predictive Analytics)」が注目を集めている。
SAP Predictive Analyticsの特徴と利点の主は下記になる。
- ビジネステーマ、データがそろっていれば、統計的な前提に基づくデータの変換、アルゴリズムの選定やチューニングが不要
- 非常にスピーディーに予測モデルの構築を行える
- 予測モデルの構築において必要となる多くのステップが自動化されている
- 操作担当者のスキルや経験にかかわらず、同じデータを投入すると全員同じ結果を出すことができる
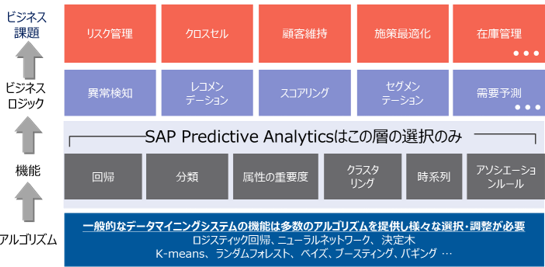
図 2. SAP Predictive Analytics の機会学習機能
4. SAP Predictive Analyticsの強み
SAP Predictive Analyticsを活用することで、業務担当者は多くの予測分析モデルを、安全かつ大量に構築することが可能となり、日常業務における多くの意思決定を機械学習のテクノロジーに基づいてデータドリブンで行えるようになる。
さらに、その予測結果となる数式は、SQL、UDF、SAS言語、Hive SQL、Spark SQL、JAVAなどの多くの言語に出力でき、様々なシステムに組み込んで独立して運用することもできるため、システム担当者の工数削減にも大きく貢献することができる。
ここでSAP Predictive Analyticsの強みを紹介しよう。
4-1.SAP HANA 連携による柔軟性の高いデータ加工
SAP Predictive Analyticsのデータ加工機能においては、HANA information Viewを活用出来ることにより、柔軟性が高いデータ加工を可能とする。
また、SAP HANA 2.0 / SAP HANA 2.0 Expressのサポートデータソース追加や、HANA Multitenant Database Containersもサポートされている。
4-2. モデリング処理の高速化
SAP Predictive Analyticsでは SparkやSAP Vora1.4に対応し、モデリングの高速化を実現できる。
予測分析領域におけるデータは日々増加の傾向にあり、いかにインメモリエンジンを活用しモデリング処理の高速化を実現するかが重要となる。
図 3 は、インメモリ上でモデル作成した場合のベンチマーク結果だ。15,000列 x 500,000行の大量データを用いてモデルを作成した場合、インメモリ上でもモデリングでは通常より10倍以上のパフォーマンスを発揮できることが確認されている。
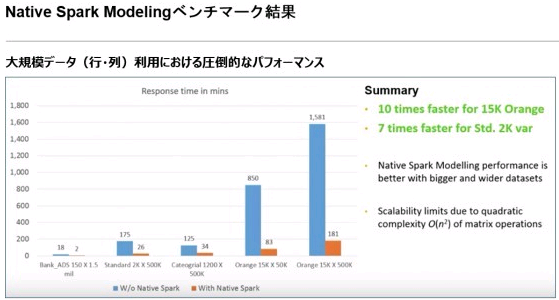
図 3. Native Spark Modelingにおけるベンチマーク
4-3. 機械学習の運用管理機能
予測分析モデルを作成した後に重要となる点は、ビジネスデータの増加に追従して、予測分析モデルの精度を維持する運用である。
SAP Predictive Analyticsでは、以下がサポートされている。
- モデル精度を継続的に監視
- 新規モデル作成(分類・回帰、時系列)
- スケジュールによるモデルの再学習・適用(スコアリング)作業の自動化
- 定期的なスケジューリング
- イベントやプログラムをトリガーとしたスケジューリング
また、モデル評価やシミュレーション用のレポート画面も用意されている。
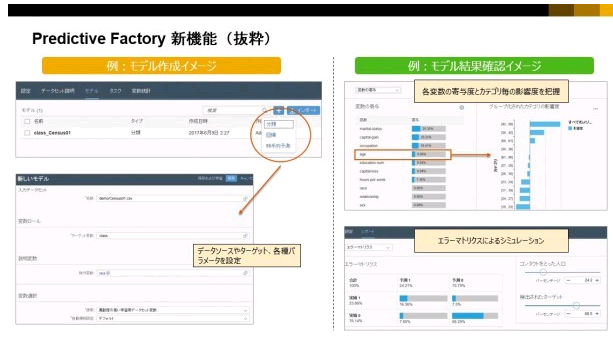
図 4. Predictive Factoryによる新規モデル作成(左図)、
モデル作成後の評価レポート(右図)
さいご
これまでデータサイエンティストの専門領域であった分析領域が簡易化・自動化できるようになりつつある昨今、業務ユーザーが中核となって人事、会計、生産、その他領域等においても機械学習を活用していくことになるだろう。
また、新たなデジタルイノベーションシステムの仕組みとして「SAP Leonardo」がある。
SAP Leonardo には、機械学習、IoT、ビックデータ、アナリティクス、ブロックチェーン等の様々なソフトウェア機能を統合でき、SAPアプリケーションへの連携はもちろん、深層学習を利用した動画や画像分析の仕組みなどを実現できる。
SAP Leonardo の概要については、以下よりご覧いただくことできる。






